A Prompt Engineering Experiment in Quantum Physics
mikelixiangIn the realm of quantum, LLMs such as gpt-4 suffer from hallucinations, logic mistakes, and incorrect conclusions when answering questions. Since gpt-4 usually formats its response in a professional and convincing manner, these mistakes made by gpt-4 can be especially misleading to users. One proposed solution to deal with this problem is through prompt engineering.
In this experiment, we would like to investigate the effect of prompt engineering on the performance of gpt-4 in answering quantum-related questions. Our contributions are as follows:
- We introduce an evaluation metric to evaluate the logic robustness and correctness of the response
- We compare the results of 4 different levels of prompt-engineered response
- We compare manual evaluation with two different techniques of automated evaluation
The Evaluation Method:
Evaluating the performance of LLM has been the subject of much research. Existing evaluation methods are categorized into manual subjective evaluation and automatic objective evaluation. It is important to note that each type of evaluation has its own limitations. Manual subjective evaluations are expensive to perform and often subject to varying standards, and automatic evaluation often fails to generate conclusive insights through their evaluation methods [1]. Existing automated evaluation includes BiLingual Evaluation Understudy (BLEU) [2], BERTScore[3], and LLM Eval [4] focus extensively on capturing the semantic behavior of LLMs. While these works are inspiring, our focus is on evaluating the robustness and correctness of the answer rather than semantic relevance. Therefore we propose the following grading metric:
- 3 points to the conclusion (deduct all if not relevant or incorrect, partial if partially correct)
- 4 points to logic and reasoning (deduct 2 for each inconsistency, deduct 1 for each minor mistake)
- 3 points to hallucination (deduct 1 for each wrong statement in the answer)
We approach grading in three different ways. The first approach is manual grading (manual), in which the order of answers to each question is shuffled to reduce bias (so the grader does not know which response is the result of which technique). The grader then compares the response with the sample answer to grade. The second approach is automatic (auto_1), where we provide gpt-4 with an answer and rubric, and prompt get-4 for grading in a zero-shot manner. The third approach is also automatic (auto_2), but gpt-4 is now prompted to generate an answer based on the sample answer first, and then use its answer as the key to grade the response. In this way, the grader keeps a better version of its own response as the benchmark (assume the quality of the response is directly and positively correlated to the relevance and correctness of the prompt).
The responses to each question are generated by gpt-4 in four different flavors. Aside from the one with no hint, we have three prompts with hints of different levels of relevance. The unrelated hints are hints about a difficult quantum-related topic, but may not be relevant to the question at all. The vague hints are hints that are relevant to the topic of the question, but not directly related to what the question is asking. For example, if a question is about the variational principle, a vague hint can be a solution to a different problem related to the variational principle, or some knowledge and calculation about the variational principle in general. The insightful hint is a hint that is relevant to the question. These can be a suggestion on the methodology of the answer, or a solution to a similar or related problem. It has been shown in previous studies that the manual chain of thought is an effective strategy, the hypothesis is that the the performance of gpt-4 is directly related to the relevance of the hint (assume correct) in the prompt [5].
Dataset
I gather questions from different chapters of Introduction to Quantum Mechanics (3rd Edition) by David J. Griffiths, Darrell F. Schroeter. I reformatted the questions and handpicked different hints for each question. There are a total of 10 questions, 30 hints, and 10 answers.
Results
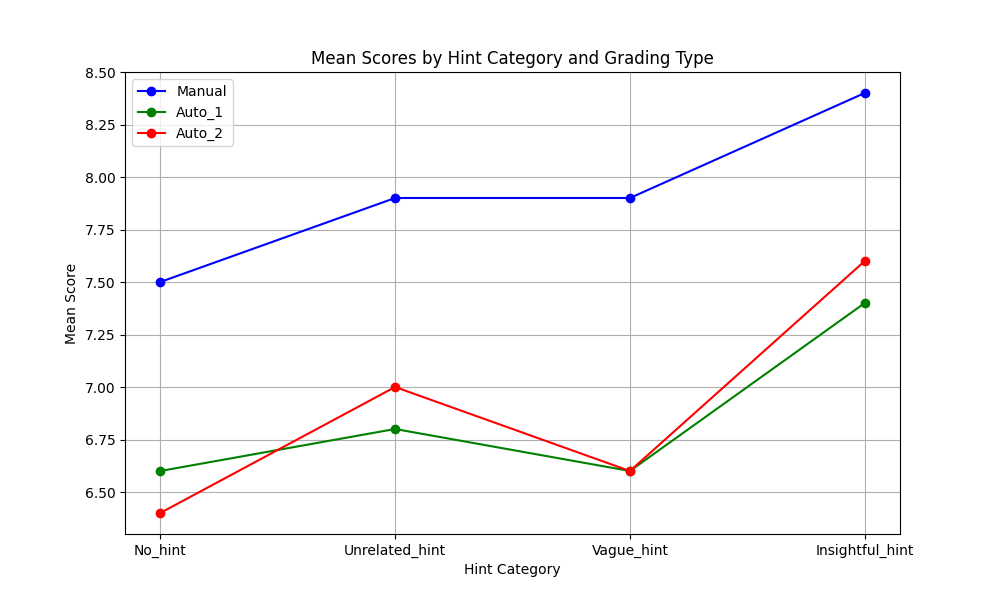
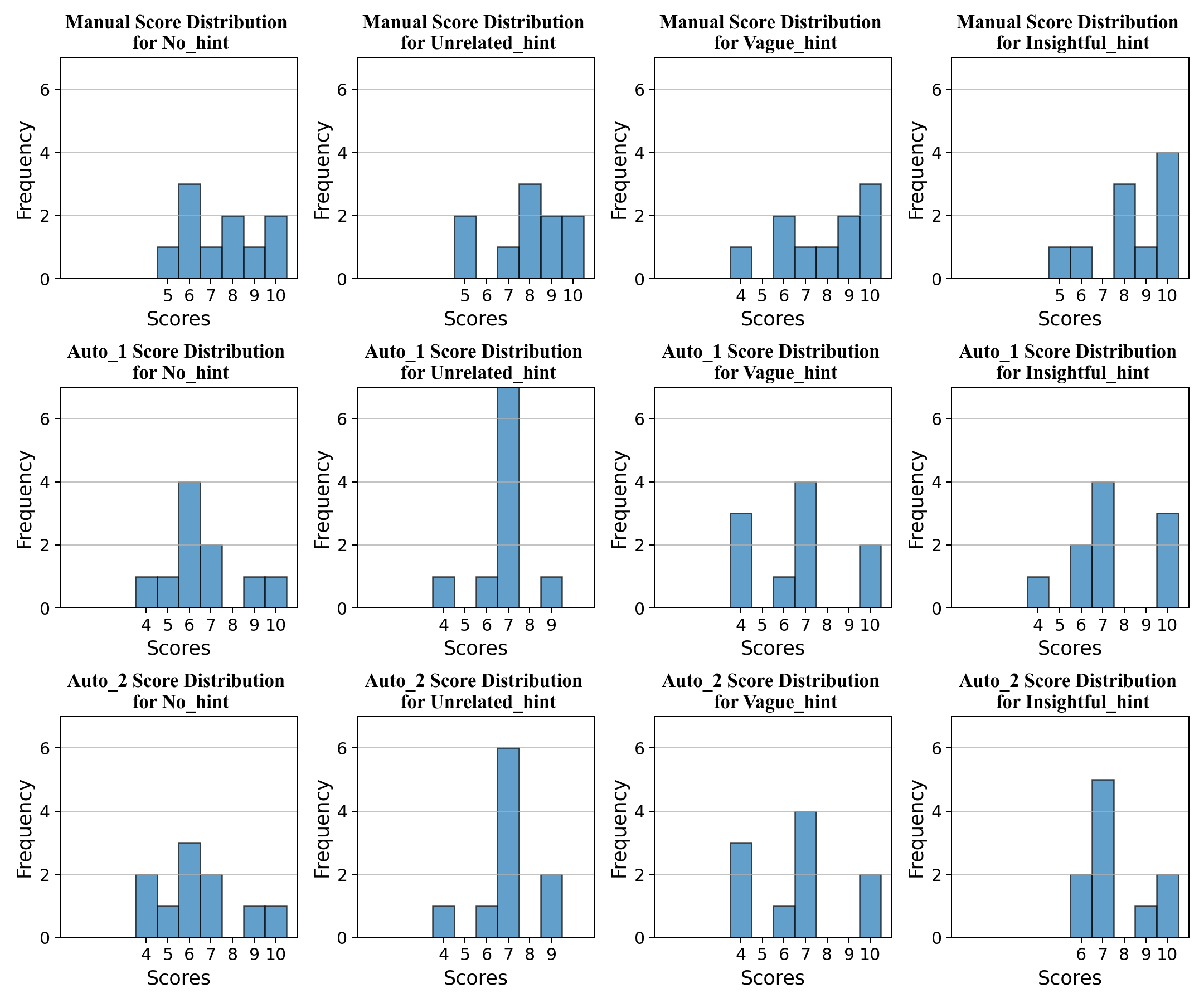
The results are shown in the following figures. We have two tables showing the mean and standard deviation of grading. We also have two figures. The top one is the score distribution for different hints and different types of grading, and the bottom one is a plot for the mean score under different types of grading.
| No_hint | Unrelevant | Vague | Insightful | |
| Manual | 7.5 | 7.9 | 7.9 | 8.4 |
| Auto_1 | 6.6 | 6.8 | 6.6 | 7.4 |
| Auto_2 | 6.4 | 7.0 | 6.6 | 7.6 |
| No_hint | Unrelevant | Vague | Insightful | |
| Manual | 1.69 | 1.70 | 1.97 | 1.69 |
| Auto_1 | 1.69 | 1.17 | 2.11 | 1.91 |
| Auto_2 | 1.85 | 1.34 | 2.11 | 1.43 |
Conclusion
The auto_1 grading and auto_2 grading are statistically similar. However, the manual grading is statistically different from both of them. The consensus among all three gradings is as follows: 1. insightful hints improve performance in terms of mean score significantly. 2. No_hint has the worst performance in terms of mean score. The performance difference between unrelated_hint and vague_hint is more controversial.
Our results suggest that highly relevant hints improve the performance of gpt-4 significantly in answering quantum-related questions, and performance under some correct hints is at least as good as no_hint. This supports our initial hypothesis. Our result also suggests that unrelated_hint is at least as good as vague hint in terms of mean score performance. This behavior is not predicted by our hypothesis as vague_hints are meant to be more relevant than unrelated_hints. One possible explanation is that the human perception of relevance may not be completely aligned with the model. So a hint that looks relevant and helpful to me may not be helpful to gpt-4 in some cases.
Limitations and Future Research
1. The dataset is small, future research can work on expanding the dataset with more questions, hints, and answers.
2. Future research can investigate the effect of including multiple hints of different types and correctness
3. Future research can develop an auto-grader with a few-shot approach by utilizing a manual or even automatic chain of thoughts.
4. Future research can investigate the misalignment between the perceived helpfulness of hints by humans and by models.
Code Availability:
https://github.com/mikelixiang88/quantum_grader
Reference:
[1] Chen B, Zhang Z, Langrené N, Zhu S. Unleashing the potential of prompt engineering in Large Language Models: a comprehensive review. In: arXiv preprint arXiv:2310.14735v2; 2023.
[2] Papineni K, Roukos S, Ward T, Zhu WJ. BLEU: a method for automatic evaluation of machine translation. In: Proceedings of the 40th Annual Meeting on Association for Computational Linguistics; 2002. p. 311–318.
[3] Zhang T, Kishore V, Wu F, Weinberger KQ, Artzi Y. BERTScore: evaluating text generation with BERT. In: International Conference on Learning Representations; 2020.
[4] Lin YT, Chen YN. LLM-eval: unified multi-dimensional automatic evaluation for open-domain conversations with large language models; 2023. ArXiv:2305.13711.
[5] Jason Wei, Xuezhi Wang, and Dale Schuurmans. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837.
Comments
Hello this is Mike, the author of this article
Posted on: Nov. 13, 2023, 11:12 p.m.